
Abstract
Aims/hypothesis
The associations between adiponectin polymorphisms and type 2 diabetes have been studied widely; however, results are inconsistent.
Methods
We searched electronic literature databases and reference lists of relevant articles. A fixed or random effects model was used on the basis of heterogeneity. Sub-group and meta-regression analyses were conducted to explore the sources of heterogeneity.
Results
There were no statistically significant associations between +45T>G (rs2241766), +276G>T (rs1501299), −11391G>A (rs17300539) and type 2 diabetes risk. However, for −11377C>G (rs266729), the pooled OR (95% CI) for G vs C allele was 1.07 (1.03–1.11, p = 0.001). Subgroup analysis by study design revealed that −11377C>G (rs266729) dominant model (CG+GG vs CC, p = 0.0008) and G vs C allele (p = 0.0004) might be associated with type 2 diabetes risk in population-based case–control studies. After stratification by ethnicity, we found that −11377C>G (rs266729) dominant model (CG+GG vs CC, p = 0.004) and G vs C allele (p = 0.001) might be associated with type 2 diabetes risk in white individuals. In individuals with a family history of diabetes, the presence of −11391G>A (rs17300539) dominant model (GA+AA vs GG) and A vs G allele might be associated with increased risk of type 2 diabetes.
Conclusions/interpretation
The presence of +45T>G (rs2241766), +276G>T (rs1501299) and −11391G>A (rs17300539) do not appear to influence the development of type 2 diabetes. However, G vs C allele of −11377C>G (rs266729) might be a risk factor for type 2 diabetes.
Similar content being viewed by others
Introduction
The incidence of diabetes is increasing worldwide. It is estimated that 250 million people will have diabetes by the year 2020, the most of whom will have type 2 diabetes mellitus [1]. Therefore, prevention and treatment of type 2 diabetes is a global health priority [2].
It is well recognised that insulin resistance plays an important role in the development of type 2 diabetes and that multiple mechanisms contribute to its pathogenesis [3]. Among these, the role of adipose tissue is of significance. Adipose tissue was previously regarded merely as an energy-storing organ, but now it is recognised as an active endocrine organ with autocrine regulation, secreting a variety of proteins that influence metabolism [4]. In recent years, there has been increased interest in the role of those secreted proteins. Among them, adiponectin (encoded by ADIPOQ [also known as APM1, ACRP30 or GBP28]) is the most abundant adipokine in human plasma and has gained considerable attention, particularly in the pathophysiology and genetics of type 2 diabetes.
A susceptibility locus for metabolic syndrome and diabetes has been mapped to human chromosome 3q27 [5], where the adiponectin gene is located [6, 7]. Adiponectin has insulin-sensitising, anti-inflammatory, anti-atherogenic properties and plays a critical role in the development of insulin resistance [8]. In a longitudinal study of rhesus monkeys, plasma levels of adiponectin declined during the early stage of obesity and continued to decrease with the development of insulin resistance and type 2 diabetes. This demonstrated that circulating plasma adiponectin levels decreased in parallel with reduced insulin sensitivity [9]. In another study, treatment of mice with purified recombinant adiponectin resulted in increased plasma adiponectin and short-term reductions in glucose levels [10]. Yamauchi et al. reported that physiological doses of adiponectin improved glucose tolerance and insulin sensitivity among animals maintained on a high-fat diet [11]. These studies support the proposition that adiponectin has a significant role in regulating insulin sensitivity in individuals with obesity and diabetes, and that decreased plasma adiponectin levels contribute to insulin resistance and type 2 diabetes.
Population-based human studies have shown that plasma adiponectin concentration is relatively low in individuals with obesity, insulin resistance and type 2 diabetes [12]. A follow-up study of 1,792 Japanese reported that patients with low adiponectin levels had a 9.3-fold risk of developing type 2 diabetes than patients with high adiponectin levels [13]. Among the diabetes-susceptible Pima Indians, individuals with high adiponectin levels were protected against type 2 diabetes [14].These studies indicate that adiponectin plays an important role in the pathogenesis of type 2 diabetes and that low levels of adiponectin serve as predictor of insulin resistance and type 2 diabetes. Moreover, there is a growing interest in identifying and examining the promising role of adiponectin, as it may serve as an important physiological and pharmacological target in the prevention and treatment of type 2 diabetes, particularly among individuals with adiposity, insulin resistance and dyslipidaemia.
Evidence that the candidate gene ADIPOQ has a clear association with adiponectin levels is strong. This relationship has been validated by several genome-wide association studies (GWAS) [15–18]. In the GWAS analyses by Ling et al. and Heid et al., ADIPOQ locus was detected as the major gene for plasma adiponectin levels [15, 16]. Several single-nucleotide polymorphisms (SNPs) of ADIPOQ gene have been reproducibly reported to be associated with variations in the levels of circulating adiponectin. Vasseur et al. demonstrated that higher adiponectin levels were associated with variant alleles of −11391G>A (rs17300539), whereas variant alleles at −11377C>G (rs266729) were associated with lower adiponectin levels [19]. Another study found that +45T>G (rs2241766) and 276+G>T (rs1501299) may act through decreased adiponectin expression, which may in turn cause increased body weight and insulin resistance [20]. Moreover, a meta-analysis by Menzaghi et al. indicated that variants in ADIPOQ played a role in modulating adiponectin secretion [21].
It is well documented that adiponectin levels are highly heritable (30–70%) [19, 21, 22] and inversely associated with risk of type 2 diabetes mellitus. Common variants in the ADIPOQ gene may harbour targets for new drugs [23]. Currently the mechanism of how adiponectin works is still unclear, but identification of its susceptibility loci for type 2 diabetes may offer some important clues. The four most relevant SNPs of adiponectin that have attracted increasing interest among researchers are +45T>G (rs2241766) in exon 2, +276G>T (rs1501299) in intron 2, and −11377C>G (rs266729) and −11391G>A (rs17300539) in the promoter [24]. Numerous studies from many different ethnic populations have investigated the associations of the above mentioned adiponectin polymorphisms with type 2 diabetes [19, 20, 25–55]. However, results have been conflicting, with some studies demonstrating positive associations, while others have shown the opposite. Importantly, many of these studies involved a limited sample size, which may have affected their reliability.
Staiger et al. have also referred to ADIPOQ on chromosome 3q27 as another well-replicated biological candidate gene not yet confirmed by GWAS or large meta-analyses, and therefore still classified as a potential diabetes risk gene [56]. Therefore, we undertook a systematic review and meta-analysis of all published studies on the topic (for which adequate data were available) to determine the associations between adiponectin SNPs and type 2 diabetes. Further in depth exploration of this association will contribute to a better understanding of the role of adiponectin in insulin resistance and type 2 diabetes. In turn, this could help identify and manage high-risk populations for diabetes, as well as pointing towards new molecular targets for future therapeutic interventions.
Methods
Literature search
We systematically searched MEDLINE, EMBASE, Elsevier, Springer, EBSCO, Highwire Press, LWW, ISI Web of Science and Cochrane Library databases for relevant articles from their starting dates to February 2011 using the terms: ‘Adiponectin’ ‘type 2 diabetes’ ‘apM1’ ‘ADIPOQ’ ‘ACDC’ ‘Acrp30’ ‘Gbp28’‘single nucleotide polymorphism (SNP)’ ‘gene’ and various synonyms. We supplemented this search by scanning the reference lists of relevant articles. The search was limited to work published in English language.
All identified abstracts were reviewed by two reviewers (L. Y. Han, M. M. Zhao) independently for eligibility. Full-text reports were reviewed and included if they met the following criteria: (1) original study of human participants, regardless of sample size; (2) study reporting on the associations between +45T>G (rs2241766), +276G>T (rs1501299), −11377C>G (rs266729) and −11391G>A(rs17300539) of adiponectin gene and type 2 diabetes; (3) study design was (nested) case–control study or cohort study; (4) genotype distribution in controls were in Hardy–Weinberg equilibrium (to limit heterogeneity and ensure quality of data); (5) type 2 diabetes was clinically defined as a disease with gradual adult onset, and type 1 diabetes, MODY and mitochondrial diabetes were excluded; and (6) in the event of duplicate publications from the same patient population, only the paper that had the largest population or otherwise contained more useful information was included.
Data extraction
For each article included in this study, data were extracted using a standardised data extraction form by the reviewers (L. Y. Han, M. M. Zhao). Disagreement between two reviewers was resolved by involving a third reviewer (Q. H. Wu). For each article included in the meta-analysis, the following information was extracted: first author name, year of publication, ethnicity, sample size, genotype distribution among cases and controls, genotyping methods, study design, major variant allele frequency in cases and controls, family history of diabetes, definition of cases, and covariates controlled by matching or multivariable analysis (age, sex, BMI, etc.). Study designs were categorised as case–control (hospital-based and population-based studies) and cohort studies. Race/ethnicity was categorised as Asian, white and others. A double-check procedure was performed to ensure accuracy of data entry.
Study quality was assessed following the guidelines for case–control studies proposed by Lichtenstein et al. [57] and a quality assessment score was developed for genetic association studies [58] based on traditional epidemiological and genetic considerations [59]. Any discrepancies were adjudicated by a third reviewer (Q. H. Wu).
Statistical analysis
Odds ratios with 95% CIs were calculated to assess the associations between +45T>G (rs2241766), +276G>T (rs1501299), −11377C>G (rs266729) and −11391G>A (rs17300539) of adiponectin gene and type 2 diabetes risk. We explored the association between +45T>G (rs2241766) and type 2 diabetes in a general model (GG vs TT; GG vs TG), dominant model (GG +TG vs TT), recessive model (GG vs TG +TT) and G allele vs T allele, respectively. The same genetic models were performed for the other three SNPs. Statistical analyses were performed using STATA (10.1; Stata Corporation, College Station, TX, USA).
Cochran’s Q test was used to assess heterogeneity among studies. If the Q-test revealed a p value of p > 0.10, the fixed-effects model (the Mantel–Haenszel method) was selected to pool the data [60]. Otherwise, the random-effects model (the DerSimonian and Laird method) was used [61]. We carried out ten independent tests for each genetic model of the four SNPs. To reduce type I error induced by multiple tests, Bonferroni’s adjustment was applied to the significance thresholds. This employs the formula \( 1 - {\left( {{1} - \alpha } \right)^{{1/{{n}}}}} \) to adjust the significance level and maintain an error rate of 0.05 [62]. After strict adjustment by multiple testing, which resulted in a very stringent p value and led to the conclusion that it would be too conservative and increase the probability of getting false-negative results, after careful consideration a p value of p < 0.005 was adopted as the significant threshold across the four SNPs for each genetic model.
Potential publication bias was estimated using a funnel plot, in which the standard error of log (OR) of each study was plotted against its log (OR) (a measure of study size). As a supplement to the funnel plot, we also used the linear regression approach proposed by Egger et al. [63] to evaluate publication bias with quantitative analysis. If publication bias existed, the trim and fill method was used to produce an adjusted pooled OR and 95% CI [64].
Sub-group and sensitivity analyses were conducted. Sub-group analyses were conducted among studies by subdividing design (hospital and population-based case–control studies, cohort studies), ethnicity (Asian, white and others) and presence of family history of diabetes. One-way sensitivity analyses were performed to assess the stability of results.
For further exploration of heterogeneity, meta-regression analyses were conducted by including the variables age, sex, BMI and genotyping methods used for cases and controls. For studies that reported incomplete genotype data, we calculated genotype using other available information in the reports such as allele frequencies. Hardy–Weinberg equilibrium was tested using means of the exact χ 2 test.
To further verify our meta-analysis findings and get more convincing results, we also applied to the Diabetes Genetics, Replication And Meta-Analysis (DIAGRAM)+ consortium, requesting their GWAS test results on the relationship between the four identified SNPs and type 2 diabetes [65]. After very carefully reviewing the list of cohorts involved in DIAGRAM+ [65], we excluded the duplicated cohorts from our meta-analysis, then combined the OR (95% CI) and p values of DIAGRAM+ (stage 2) [65] with our own OR (95% CI) and p values for an additive test for each SNP. By conducting this much larger sample sized meta-analysis by STATA, we expected to get a more powerful result.
Results
Description of studies
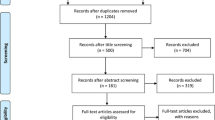
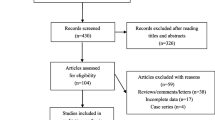
The initial search yielded 2,510 references. Based on titles and/or abstracts, we excluded 2,298 and reviewed 212 full text reports. Applying the study inclusion criteria, 33 studies were included in this meta-analysis (Fig. 1). Also included were: 21 relevant studies with a total number of 6,370 cases and 15,443 controls were included in +45T>G (rs2241766) analysis, 21 relevant studies with a total number of 7,958 cases and 18,765 controls were included in +276G>T (rs1501299) analysis, 16 relevant studies with a total number of 6,127 cases and 12,097 controls were included in −11377C>G (rs266729) analysis and 12 relevant studies with a total number of 4,139 cases and 12,530 controls were included in −11391G>A (rs17300539) analysis.

Study flow diagram
Of the 33 studies (see Table 1), 11 were hospital-based case–control studies [25–35], 11 were population-based case–control studies [19, 20, 36–44], one was a nested case–control study [45] and ten were cohort studies [46–55]. A total of 12 studies included Asian individuals and 16 included white individuals; the participants in the remaining studies were Pima Indians, Japanese-Brazilian, black South African, Mexican and Iranian. The characteristics of study groups and patient overall demographics are shown in Table 1.
Associations between the four SNPs of adiponectin gene and type 2 diabetes
The meta-analysis revealed that there were no statistically significant associations between the SNPs +45T>G (rs2241766), +276G>T (rs1501299) and −11391G>A (rs17300539) and type 2 diabetes risk (Table 2, Electronic supplementary material [ESM] Tables 1, 2, 3). In contrast, we found that −11377C>G (rs266729) in the proximal promoter might be associated with type 2 diabetes risk. The pooled OR (95% CI) for G vs C allele of −11377C>G (rs266729) was 1.09 (1.03–1.15, p = 0.001) (not including DIAGRAM+ data). After incorporation of DIAGRAM+ data, the meta-analysis showed the pooled OR (95% CI) for G vs C allele of −11377C>G (rs266729) to be 1.07 (1.03–1.11, p = 0.001) (Fig. 2, Table 2, ESM Table 4).

Forest plot for the association between type 2 diabetes risk and −11377C>G (rs266729) for G vs C allele in the overall populations. The square represents the point estimates of the odds ratio for each study. Each square is proportional to the percentage weight of each study in the overall meta-analysis. The diamond represents the overall summary estimate, with confidence interval given by its width. The unbroken vertical line is at the null value (OR = 1.0)
Studies with population-based case–controls vs hospital-based case–controls
Data in ESM Table 4 show that −11377C>G (rs266729) might be associated with type 2 diabetes risk in population-based case–control studies (CG+GG vs CC, p = 0.0008, G vs C allele, p = 0.0004).
No statistically significant associations between SNPS +45T>G (rs2241766), +276G>T (rs1501299) and −11391G>A (rs17300539) and type 2 diabetes were found either in the hospital-based case–control studies, or in the population-based case–control studies (ESM Tables 1, 2, 3).
Ethnicity
Stratification by ethnicity revealed that −11377C>G (rs266729) dominant model (CG+GG vs CC, p = 0.004) and G vs C allele (p = 0.001) might be associated with type 2 diabetes risk in white individuals (findings from DIAGRAM+ meta-analysis incorporated) (ESM Table 4).
Associations between +45T>G (rs2241766) dominant model (GG+TG vs TT) and type 2 diabetes tended to be stronger for Asian than for other ethnicities, but these differences were not statistically significant (ESM Table 1).
Family history of diabetes
In individuals with family history of diabetes, analysis showed that the presence of −11391 G>A (rs17300539) dominant model (GA+AA vs GG, p = 0.001) and A vs G allele (p = 0.001) might be associated with type 2 diabetes risk (ESM Table 3).
Meta-regression
In the meta-analysis, most of the studies were adjusted for known confounding factors such as age, sex, BMI etc. Original data on age, sex, BMI and other variables in cases and controls were obtained from available studies for each SNP. We found significant correlations between age of the cases and type 2 diabetes in +45(GG+TG vs TT, p = 0.006; G vs T allele, p = 0.007), which explained 70% and 62% of heterogeneity respectively (data not shown). However, no statistical significance was found for the genotyping methods used (data not shown).
Publication bias
Begg’s funnel plots and Egger’s tests were performed to assess publication bias. Results from small studies scattered widely at the bottom of the graph, with the spread narrowing among larger studies (Fig. 3).

Begg’s funnel plot for the association G vs C allele of −11377C>G (rs266729) in the overall population. The horizontal line in the middle represents the estimate of summary ORs and the two slant sidelines show the confine of 95% CIs. Each point represents a separate study
There was no significant publication bias for G vs C allele of −11377C>G (rs266729) (ESM Table 4). This indicates that the results of this meta-analysis are relatively stable and that publication bias is unlikely to have affected the results. The sensitivity analyses also indicated that results of our study are stable and reliable (data not shown).
Discussion
This meta-analysis demonstrated that the presence of +45T>G (rs2241766), +276G>T (rs1501299) and −11391G>A (rs17300539) were not associated with type 2 diabetes risk. DIAGRAM+ (a complex disease GWAS scan meta-analysis), which involved 34,412 cases and 59,925 controls, found that the OR (95% CI) and p values for G vs C allele of −11377C>G (rs266729) was 1.06 (1.01–1.11, p = 0.011) [65].
After incorporating their data into our meta-analysis (our sample size was sufficiently powerful [93.5%] to detect the differences between case and control participants), the combined meta-analysis demonstrated that the G vs C allele of −11377C>G (rs266729) might be associated with type 2 diabetes risk, but it did not reach genome-wide significance p < 5 × 10−8. Our finding is consistent with a meta-analysis by Gong et al. [66], who also showed that −11377C>G (rs266729) and −11391G>A (rs17300539) polymorphisms might be associated with risk of type 2 diabetes in European whites. However, −11391G>A (rs17300539) in our meta-analysis was not associated with type 2 diabetes risk in whites. This difference may be partly because we set a more stringent statistically significant level of p = 0.005.
Interestingly, the ORs for −11391G>A (rs17300539) seemed to be higher than those for −11377C>G (rs266729) in most tests, but their associations were not statistically significant. One possible explanation is the small sample size for −11391 G>A (rs17300539); another may be that −11391G>A (rs17300539) did not actually have association with type 2 diabetes. In addition, the ethnicity involved in these two SNPs was different (the majority of populations for −11391G>A rs17300539 were white; while those for −11377C>G rs266729 were white or Asian). It is important to note that if Bonferroni’s correction were strictly adopted (0.00025), the p values obtained in our study would not retain their significance. This correction may be too conservative and increase the chance of type II error. We therefore adopted a less strict level of statistical significance (p = 0.005).
Through the meta-regression, we found that age in cases was a potential risk factor for type 2 diabetes in +45T>G (rs2241766) populations. This may explain some of the heterogeneity for +45(GG+TG vs TT, 70%) and (G vs T allele, 62%) respectively. This also provides some evidence that the association between +45(GG+TG vs TT; G vs T allele) and type 2 diabetes might be mediated by age. Therefore, stratified analyses for age should be considered in future studies.
Among individuals with a family history of diabetes, the presence of −11391G>A (rs17300539) dominant model (GA+AA vs GG) and A vs G allele might be associated with type 2 diabetes risk. In contrast, the presence of +45T>G (rs2241766) appeared to have no effect in cases without a family history of diabetes. This result differs from that of Stumvoll et al. [67], who showed that the presence of +45T>G (rs2241766) mildly increased obesity risk and secondarily caused insulin resistance in individuals without family history of diabetes. The reasons for this discrepancy may be related to variation across studies in ethnic background, environmental factors, sample size and other factors.
In 2007, Menzaghi et al. conducted a meta-analysis to explore the associations of different adiponectin SNPs with insulin resistance, type 2 diabetes and cardiovascular disease [21]. However, Menzaghi and colleagues did not observe significant global effects between any of the four SNPs considered in their meta-analysis. This is slightly different from our study, for we found that G vs C allele of −11377C>G rs266729 might be associated with type 2 diabetes risk. There are three possible explanations for this inconsistency. First, the difference may be due to the sample size, for a large expanding body of literature assessing associations between risk of type 2 diabetes and adiponectin SNPs has been published since 2007, but were not included in the meta-analysis by Mezaghi et al. Second, not all of the included studies (control population) in Menzaghi et al. were in Hardy–Weinberg equilibrium. Third, the analysis by Menzaghi et al. included a study that observed patients with end-stage renal disease [68].
So far, several genetic variants in the adiponectin gene have been identified and their associations with type 2 diabetes studied. It is noteworthy that +45T>G (rs2241766) and +276G>T (rs1501299) were closely associated with susceptibility to type 2 diabetes in a Japanese population [25], but not in French or Swedish whites [37, 38], while 45TG+GG and 276GG were associated with increased risk of type 2 diabetes in Chinese populations [69]. However, our meta-analysis did not find significant associations between the SNPs +45T>G (rs2241766) and +276G>T (rs1501299) and type 2 diabetes in Asians and whites. One possible explanation is that different populations may have experienced very diverse environmental impacts during their evolution. In addition, different life style as well as study sample size might also have contributed to this difference. Interestingly, significantly increased risks were found in population-based case–control studies for dominant model and G vs C allele of −11377C>G (rs266729); this may be due to the ethnicity of these study populations, which were mainly white; other reasons may be different sample size etc.
The results presented in this study should be interpreted with particular caution when heterogeneity was present. Obvious heterogeneity was observed in hospital-based case–control populations. In addition, heterogeneity also existed in Asian populations. This suggests that the effect of genetic background and environmental history on diabetes varied by ethnicity. Other contributing factors may be variable definition of cases and controls, sample size, genotype errors and publication bias etc.
The strength of this analysis is that we included the most updated literature on the relationship between the four SNPs of adiponectin and type 2 diabetes. To guarantee the quality of this study, we used explicit criteria for study inclusion and a strict procedure for data extraction. Results, moreover, are statistically robust and conclusions are sound. We also conducted meta-regression including age, sex, BMI and genotyping methods. Besides, it is increasingly recognised that meta-analysis of GWAS datasets can increase the power to detect association signals by increasing sample size and examining more variants comprehensively throughout the entire genome datasets [70]. Therefore we also incorporated the results of a large-scale association analysis (DIAGRAM+) [65] to make our study much better powered and meta-analysis more informative.
Limitations of this meta-analysis are: first, our search was limited to published English-language studies, with studies published in other languages systematically excluded. This may explain some publication bias in our meta-analysis, which may have affected the results of this meta-analysis in as far as those studies that had produced negative results might not have been published. Second, since we were not able to obtain the original data, our further evaluation of potential interactions (gene × gene, gene × environment etc.) was limited. Third, not all of the included studies were adjusted for potential confounders (age, sex, BMI etc.), all of which could have influenced the relationship between the four SNPs and risk of type 2 diabetes.
It is well documented that ADIPOQ gene is quite polymorphic, and that some polymorphisms in the same gene and different genes may exert a combined effect on susceptibility to type 2 diabetes. It is also possible that polymorphisms of ADIPOQ gene may be in linkage disequilibrium with a yet unidentified mutation that obstructs the biological function of adiponectin. Thus the clarification of how these adiponectin polymorphisms interact with each other is worthy of future concern. Therefore, studies investigating the functionality associated with these polymorphisms and comprehensive interactions at gene × gene and gene × environment level are needed in future.
Our meta-analysis identified an association between the G vs C allele of −11377C>G (rs266729) and type 2 diabetes. This might indicate that 11377C>G (rs266729) is a potential functional variant, which influences the abundance expressor function of adiponectin. The application, therefore, of bio-informatics tools and datasets to assess and validate that function could be of great importance in helping us to understand how ADIPOQ expression is regulated, as well as to clarify the physiological role of this gene and its mechanism during the development of type 2 diabetes.
Till now, many updated research projects have demonstrated that adiponectin has the ability to reduce insulin resistance in conjunction with anti-inflammatory and anti-atherogenic properties. Therefore, enhancing adiponectin secretion or action is likely to have a significant therapeutic value, with therapeutic modulation of adiponectin possibly providing novel clinical intervention strategies for obesity, diabetes and metabolic syndrome etc. [71]. In this sense, the progress of adiponectin analogues holds great promise for clinical use in improving insulin sensitivity and preventing atherosclerotic disease [72].
Abbreviations
- DIAGRAM:
-
Diabetes Genetics, Replication And Meta-Analysis
- GWAS:
-
Genome-wide association study
- SNP:
-
Single-nucleotide polymorphism
References
King H, Aubert RE, Herman WH (1998) Global burden of diabetes, 1995–2025: prevalence, numerical estimates, and projections. Diabetes Care 21:1414–1431
Wild S, Roglic G, Green A, Sicree R, King H (2004) Global prevalence of diabetes: estimates for the year 2000 and projections for 2030. Diabetes Care 27:1047–1053
Stumvoll M, Goldstein BJ, van Haeften TW (2005) Type 2 diabetes: principles of pathogenesis and therapy. Lancet 365:1333–1346
Kershaw EE, Flier JS (2004) Adipose tissue as an endocrine organ. J Clin Endocrinol Metab 89:2548–2556
Vionnet N, Hani EH, Dupont S et al (2000) Genomewide search for type 2 diabetes-susceptibility genes in French whites: evidence for a novel susceptibility locus for early-onset diabetes on chromosome 3q27-qter and independent replication of a type 2-diabetes locus on chromosome 1q21-q24. Am J Hum Genet 67:1470–1480
Kissebah AH, Sonnenberg GE, Myklebust J et al (2000) Quantitative trait loci on chromosomes 3 and 17 influence phenotypes of the metabolic syndrome. Proc Natl Acad Sci USA 97:14478–14483
Yamauchi T, Kamon J, Waki H et al (2001) The fat-derived hormone adiponectin reverses insulin resistance associated with both lipoatrophy and obesity. Nat Med 7:941–946
Scherer PE (2006) Adipose tissue: from lipid storage compartment to endocrine organ. Diabetes 55:1537–1545
Hotta K, Funahashi T, Bodkin NL et al (2001) Circulating concentrations of the adipocyte protein adiponectin are decreased in parallel with reduced insulin sensitivity during the progression to type 2 diabetes in rhesus monkeys. Diabetes 50:1126–1133
Berg AH, Combs TP, Scherer PE (2002) ACRP30/adiponectin: an adipokine regulating glucose and lipid metabolism. Trends Endocrinol Metab 13:84–89
Yamauchi T, Oike Y, Kamon J et al (2002) Increased insulin sensitivity despite lipodystrophy in Crebbp heterozygous mice. Nat Genet 30:221–226
Hotta K, Funahashi T, Arita Y et al (2000) Plasma concentrations of a novel, adipose-specific protein, adiponectin, in type 2 diabetic patients. Arterioscler Thromb Vasc Biol 20:1595–1599
Daimon M, Oizumi T, Saitoh T et al (2003) Decreased serum levels of adiponectin are a risk factor for the progression to type 2 diabetes in the Japanese population: the Funagata Study. Diabetes Care 26:2015–2020
Lindsay RS, Funahashi T, Hanson RL et al (2002) Adiponectin and development of type 2 diabetes in the Pima Indian population. Lancet 360:57–58
Ling H, Waterworth DM, Stirnadel HA et al (2009) Genome-wide linkage and association analyses to identify genes influencing adiponectin levels: the GEMS Study. Obesity (Silver Spring) 17:737–744
Heid IM, Henneman P, Hicks A et al (2010) Clear detection of ADIPOQ locus as the major gene for plasma adiponectin: results of genome-wide association analyses including 4659 European individuals. Atherosclerosis 208:412–420
Richards JB, Waterworth D, O'Rahilly S et al (2009) A genome-wide association study reveals variants in ARL15 that influence adiponectin levels. PLoS Genet 5:e1000768
Jee SH, Sull JW, Lee JE et al (2010) Adiponectin concentrations: a genome-wide association study. Am J Hum Genet 87:545–552
Vasseur F, Helbecque N, Dina C et al (2002) Single-nucleotide polymorphism haplotypes in the both proximal promoter and exon 3 of the APM1 gene modulate adipocyte-secreted adiponectin hormone levels and contribute to the genetic risk for type 2 diabetes in French Caucasians. Hum Mol Genet 11:2607–2614
Gonzalez-Sanchez JL, Zabena CA, Martinez-Larrad MT et al (2005) An SNP in the adiponectin gene is associated with decreased serum adiponectin levels and risk for impaired glucose tolerance. Obes Res 13:807–812
Menzaghi C, Trischitta V, Doria A (2007) Genetic influences of adiponectin on insulin resistance, type 2 diabetes, and cardiovascular disease. Diabetes 56:1198–1209
Comuzzie AG, Funahashi T, Sonnenberg G et al (2001) The genetic basis of plasma variation in adiponectin, a global endophenotype for obesity and the metabolic syndrome. J Clin Endocrinol Metab 86:4321–4325
Wolfs MG, Hofker MH, Wijmenga C, van Haeften TW (2009) Type 2 diabetes mellitus: new genetic insights will lead to new therapeutics. Curr Genomics 10:110–118
Gable DR, Hurel SJ, Humphries SE (2006) Adiponectin and its gene variants as risk factors for insulin resistance, the metabolic syndrome and cardiovascular disease. Atherosclerosis 188:231–244
Hara K, Boutin P, Mori Y et al (2002) Genetic variation in the gene encoding adiponectin is associated with an increased risk of type 2 diabetes in the Japanese population. Diabetes 51:536–540
Menzaghi C, Ercolino T, Di PR et al (2002) A haplotype at the adiponectin locus is associated with obesity and other features of the insulin resistance syndrome. Diabetes 51:2306–2312
Lee YY, Lee NS, Cho YM et al (2005) Genetic association study of adiponectin polymorphisms with risk of type 2 diabetes mellitus in Korean population. Diabet Med 22:569–575
Ukkola O, Santaniemi M, Rankinen T et al (2005) Adiponectin polymorphisms, adiposity and insulin metabolism: HERITAGE family study and Oulu diabetic study. Ann Med 37:141–150
Li LL, Kang XL, Ran XJ et al (2007) Associations between 45T/G polymorphism of the adiponectin gene and plasma adiponectin levels with type 2 diabetes. Clin Exp Pharmacol Physiol 34:1287–1290
Yamaguchi S, Yamada Y, Matsuo H et al (2007) Gender differences in the association of gene polymorphisms with type 2 diabetes mellitus. Int J Mol Med 19:631–637
Potapov VA, Chistiakov DA, Dubinina A, Shamkhalova MS, Shestakova MV, Nosikov VV (2008) Adiponectin and adiponectin receptor gene variants in relation to type 2 diabetes and insulin resistance-related phenotypes. Rev Diabet Stud 5:28–37
Mohammadzadeh G, Zarghami N (2009) Associations between single-nucleotide polymorphisms of the adiponectin gene, serum adiponectin levels and increased risk of type 2 diabetes mellitus in Iranian obese individuals. Scand J Clin Lab Invest 69:764–771
Sun H, Gong ZC, Yin JY et al (2008) The association of adiponectin allele 45T/G and −11377C/G polymorphisms with type 2 diabetes and rosiglitazone response in Chinese patients. Br J Clin Pharmacol 65:917–926
Wang X, Zhang S, Chen Y et al (2009) APM1 gene variants −11377C/G and 4545G/C are associated respectively with obesity and with non-obesity in Chinese type 2 diabetes. Diabetes Res Clin Pract 84:205–210
Suriyaprom K, Phonrat B, Namjuntra P, Harnroongroj T, Tungtrongchitr R (2010) The −11377C>G adiponectin gene polymorphism alters the adiponectin concentration and the susceptibility to type 2 diabetes in Thais. Int J Vitam Nutr Res 80:216–224
Populaire C, Mori Y, Dina C et al (2003) Does the −11377 promoter variant of APM1 gene contribute to the genetic risk for type 2 diabetes mellitus in Japanese families. Diabetologia 46:443–445
Gu HF, Abulaiti A, Ostenson CG et al (2004) Single nucleotide polymorphisms in the proximal promoter region of the adiponectin (APM1) gene are associated with type 2 diabetes in Swedish caucasians. Diabetes 53(Suppl 1):S31–S35
Vasseur F, Helbecque N, Lobbens S et al (2005) Hypoadiponectinaemia and high risk of type 2 diabetes are associated with adiponectin-encoding (ACDC) gene promoter variants in morbid obesity: evidence for a role of ACDC in diabesity. Diabetologia 48:892–899
Yang WS, Yang YC, Chen CL et al (2007) Adiponectin SNP276 is associated with obesity, the metabolic syndrome, and diabetes in the elderly. Am J Clin Nutr 86:509–513
Magdalena S, Malgorzata M, Beata W et al (2009) Variants of the adiponectin gene and type 2 diabetes in a Polish population. Acta Diabetol 46:317–322
Wang Y, Zhang D, Liu Y et al (2009) Association study of the single nucleotide polymorphisms in adiponectin-associated genes with type 2 diabetes in Han Chinese. J Genet Genomics 36:417–423
Yang M, Qiu CC, Chen W, Xu LL, Yu M, Xiang HD (2008) Identification of a regulatory single nucleotide polymorphism in the adiponectin (APM1) gene associated with type 2 diabetes in Han nationality. Biomed Environ Sci 21:454–459
Vendramini MF, Pereira AC, Ferreira SR, Kasamatsu TS, Moises RS (2010) Association of genetic variants in the adiponectin encoding gene (ADIPOQ) with type 2 diabetes in Japanese Brazilians. J Diabetes Complications 24:115–120
Gibson F, Froguel P (2004) Genetics of the APM1 locus and its contribution to type 2 diabetes susceptibility in French Caucasians. Diabetes 53:2977–2983
Hu FB, Doria A, Li T et al (2004) Genetic variation at the adiponectin locus and risk of type 2 diabetes in women. Diabetes 53:209–213
Fumeron F, Aubert R, Siddiq A et al (2004) Adiponectin gene polymorphisms and adiponectin levels are independently associated with the development of hyperglycemia during a 3-year period: the epidemiologic data on the insulin resistance syndrome prospective study. Diabetes 53:1150–1157
de Courten BV, Hanson RL, Funahashi T et al (2005) Common polymorphisms in the adiponectin gene ACDC are not associated with diabetes in Pima Indians. Diabetes 54:284–289
Tso AW, Sham PC, Wat NM et al (2006) Polymorphisms of the gene encoding adiponectin and glycaemic outcome of Chinese subjects with impaired glucose tolerance: a 5-year follow-up study. Diabetologia 49:1806–1815
Nannipieri M, Posadas R, Bonotti A et al (2006) Polymorphism of the 3′-untranslated region of the leptin receptor gene, but not the adiponectin SNP45 polymorphism, predicts type 2 diabetes: a population-based study. Diabetes Care 29:2509–2511
Schwarz PE, Govindarajalu S, Towers W et al (2006) Haplotypes in the promoter region of the ADIPOQ gene are associated with increased diabetes risk in a German Caucasian population. Horm Metab Res 38:447–451
Gable DR, Matin J, Whittall R et al (2007) Common adiponectin gene variants show different effects on risk of cardiovascular disease and type 2 diabetes in European subjects. Ann Hum Genet 71:453–466
Olckers A, Towers GW, der Merwe Av, Schwarz PE, Rheeder P, Schutte AE (2007) Protective effect against type 2 diabetes mellitus identified within the ACDC gene in a black South African diabetic cohort. Metabolism 56:587–592
Jaziri R, Lobbens S, Aubert R et al (2006) The PPARG Pro12Ala polymorphism is associated with a decreased risk of developing hyperglycemia over 6 years and combines with the effect of the APM1 G-11391A single nucleotide polymorphism: the Data From an Epidemiological Study on the Insulin Resistance Syndrome (DESIR) Study. Diabetes 55:1157–1162
Chiodini BD, Specchia C, Gori F et al (2010) Adiponectin gene polymorphisms and their effect on the risk of myocardial infarction and type 2 diabetes: an association study in an Italian population. Ther Adv Cardiovasc Dis 4:223–230
Hivert MF, Manning AK, McAteer JB et al (2008) Common variants in the adiponectin gene (ADIPOQ) associated with plasma adiponectin levels, type 2 diabetes, and diabetes-related quantitative traits: the Framingham Offspring Study. Diabetes 57:3353–3359
Staiger H, Machicao F, Fritsche A, Haring HU (2009) Pathomechanisms of type 2 diabetes genes. Endocr Rev 30:557–585
Lichtenstein MJ, Mulrow CD, Elwood PC (1987) Guidelines for reading case–control studies. J Chronic Dis 40:893–903
Thakkinstian A, McEvoy M, Minelli C et al (2005) Systematic review and meta-analysis of the association between β2-adrenoceptor polymorphisms and asthma: a HuGE review. Am J Epidemiol 162:201–211
Attia J, Thakkinstian A, D’Este C (2003) Meta-analyses of molecular association studies: methodologic lessons for genetic epidemiology. J Clin Epidemiol 56:297–303
Higgins JP, Thompson SG (2002) Quantifying heterogeneity in a meta-analysis. Stat Med 21:1539–1558
DerSimonian R, Laird N (1986) Meta-analysis in clinical trials. Control Clin Trials 7:177–188
Morgan JF (2007) p Value fetishism and use of the Bonferroni adjustment. Evid Based Ment Health 10:34–35
Egger M, Davey SG, Schneider M, Minder C (1997) Bias in meta-analysis detected by a simple, graphical test. BMJ 315:629–634
Duval S, Tweedie R (2000) Trim and fill: a simple funnel-plot-based method of testing and adjusting for publication bias in meta-analysis. Biometrics 56:455–463
Voight BF, Scott LJ, Steinthorsdottir V et al (2010) Twelve type 2 diabetes susceptibility loci identified through large-scale association analysis. Nat Genet 42:579–589
Gong M, Long J, Liu Q, Deng HC (2010) Association of the ADIPOQ rs17360539 and rs266729 polymorphisms with type 2 diabetes: a meta-analysis. Mol Cell Endocrinol 325:78–83
Stumvoll M, Tschritter O, Fritsche A et al (2002) Association of the T-G polymorphism in adiponectin (exon 2) with obesity and insulin sensitivity: interaction with family history of type 2 diabetes. Diabetes 51:37–41
Stenvinkel P, Marchlewska A, Pecoits-Filho R et al (2004) Adiponectin in renal disease: relationship to phenotype and genetic variation in the gene encoding adiponectin. Kidney Int 65:274–281
Li S, Li L, Li K et al (2008) Association of adipose most abundant transcript 1 gene (apM1) with type 2 diabetes mellitus in a Chinese population: a meta-analysis of case–control studies. Clin Endocrinol (Oxf) 68:885–889
Zeggini E, Ioannidis JP (2009) Meta-analysis in genome-wide association studies. Pharmacogenomics 10:191–201
Matsuzawa Y (2005) Adiponectin: identification, physiology and clinical relevance in metabolic and vascular disease. Atheroscler Suppl 6:7–14
Koerner A, Kratzsch J, Kiess W (2005) Adipocytokines: leptin—the classical, resistin—the controversical, adiponectin—the promising, and more to come. Best Pract Res Clin Endocrinol Metab 19:525–546
Acknowledgements
This study was supported by grants from the National Natural Science Foundation of China (30671802) and China Medical Board (08–929). We thank the former Editor (E. Gale), the Associate Editor and four reviewers of this journal for their valuable and constructive comments on this paper. Special thanks also to B. F. Voight, M. I. McCarthy and A. P. Morris from the DIAGRAM investigating team for providing us the relevant GWAS results of the four SNPs. We acknowledge J. B. Meigs and A. K. Manning from the Framingham Offspring Study for providing the specific genotype data of the four SNPs in their study. We also thank R. Y. Liu from Laboratory of Cancer Molecular Genetics of Soochow University, People’s Republic of China, for helpful advice and suggestions.
Q. H. W. had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. Study concept and design: L. Y. H., Q. H. W., M. L. J., Y.H. H., H. S.; acquisition of data: L. Y. H., M.M. Z., Y.H. H., L. B. L., Z.K.; analysis and interpretation of data: L. Y. H., Q. H. W., Y.H. H., L. B. L.; drafting of the manuscript: L. Y. H., Q. H. W.; critical revision of the manuscript for important intellectual content: Q. H. W., D. G. L., H. Q.; statistical analysis: L. Y. H., M.M. Z., L.J. G., N.N., H. S.; study supervision: Q. H. W., D. G. L., H. Q.
Duality of interest
The authors declare that there is no duality of interest associated with this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
L. Y. Han, Y. H. Hao and L. B. Liang contributed equally to this study.
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM Table 1
Summary of OR and 95% CI for association of polymorphism +45T>G (rs2241766) with type 2 diabetes risk (PDF 105 kb)
ESM Table 2
Summary of OR and 95% CI for association of polymorphism +276G>T (rs1501299) with type 2 diabetes risk (PDF 105 kb)
ESM Table 3
Summary of OR and 95% CI for association of polymorphism −11391G>A (rs17300539) with type 2 diabetes risk (PDF 113 kb)
ESM Table 4
Summary of OR and 95% CI for association of polymorphism −11377C>G (rs266729) with type 2 diabetes risk (PDF 124 kb)
Rights and permissions
About this article
Cite this article
Han, L.Y., Wu, Q.H., Jiao, M.L. et al. Associations between single-nucleotide polymorphisms (+45T>G, +276G>T, −11377C>G, −11391G>A) of adiponectin gene and type 2 diabetes mellitus: a systematic review and meta-analysis. Diabetologia 54, 2303–2314 (2011). https://doi.org/10.1007/s00125-011-2202-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00125-011-2202-9