


Abstract
Background: Breast cancer is one of the leading types of cancer in women worldwide. Quantitative structure–activity relationship (QSAR) methods play an important role in the search for new anticancer agents. A QSAR model for cytotoxicity against the breast cancer cell line MCF7, based on hybrid optimal descriptors, has been suggested. A modified version of the hybrid descriptor is suggested. Materials and Methods: A QSAR model for the anticancer activity of 2-phenylindole derivatives was built using the Index of Ideality of Correlation (IIC), which is a new criterion for predictive potential. The calculation can be carried out with a modified version of the CORAL software. Results: The model for the anticancer activity suggested here is better than the one described in the literature. Conclusion: Taking into account the data on molecular rings together with the use of new criterion of predictive potential (IIC), the QSAR improves the prediction for anticancer activity.
Anticancer drug discovery is a complex and important field of natural sciences. Quantitative structure–activity relationships (QSARs) are not able to provide complete data on molecular architecture required for new anticancer agents, but QSARs can help reduce the time needed and cost of the search for such agents (1).
The design of new chemical compounds that are active against the breast cancer cell line MCF7 has several conceptually different approaches. These are the well-known ADMET approach (absorption, distribution, metabolism, excretion, and toxicity) (2); general virtual screening based on comparison of different molecular features (3), molecular docking (4); various chemosensitization effects (5); 2D-QSAR (6, 7); 3D-QSAR (8) with analysis of stereoselectivity (9); study of the molecular C-skeleton architecture (10); and finally, comparative analysis of different classes of molecules with anticancer potential (11-16), for example as in the above-mentioned work (1). It is to be noted, that QSAR analysis should obey principles suggested by the Organisation for Economic Co-operation and Development (OECD) (17) and recommendations of the EU chemical control regulation in the European Union (Registration, Evaluation, Authorisation and Restriction of Chemicals, REACH) (18).
The aim of the present study was to improve the CORAL model described in (1) by means of using two approaches, namely (i) using of the Index of Ideality of Correlation (IIC), which is a new criterion for the predictive potential of QSAR models (19-22); and (ii) using correlation weights, which are related to the presence of different rings in the molecular structure (23-25).
Materials and Methods
Dataset. The dataset of 102 2-phenylindole derivatives having cytotoxicity against the MCF7 breast cancer cell line was taken from the literature (1). The molecular structure of these 2-phenylindole derivatives are represented by simplified molecular input-line entry system (SMILES) (26) and the concentration of these compounds producing 50% in vitro MCF7 cellular toxicity (IC50, in nM) was transformed into the corresponding negative logarithm (pIC50). These compounds were randomly split into training, invisible training, calibration, and validation sets and were studied here. Each of the sets has a special role. The training set is the builder of the model. The invisible training set is the inspector of the model (checking whether model is satisfactory for molecules absent from the training set). The calibration set must detect the start of overtraining. The validation set is the estimator of the predictive potential of the model.
Optimal descriptor. The optimal descriptor used here was calculated as the following:
 (Eq. 1)
whereby Sk is the SMILES atom i.e. one elemental symbol (e.g. C, N, and O) or two symbols which cannot be examined separately (e.g. Cl, and Si); SSk is a combination of two SMILES atoms; similarly SSSk is a combination of three SMILES atoms; CW(Sk), CW(SSk), and CW(SSSk) are the correlation weights of the above-mentioned attributes of SMILES; NA is the number of attributes in SMILES; α is 1, i.e. the presence of rings is involved in building the model, or 0 i.e. presence of rings is not involved in building model). HARD is a descriptor characterizing SMILES as a whole (24). The C5 and C6 are descriptors characterizing rings in the molecular structure. These descriptors are calculated with the molecular graph (23-25). C5 and C6 are codes sensitive to the number of corresponding rings in the molecular structure, the presence (absence) heteroatoms, and the presence (absence) of aromaticity. Figure 1 shows the general scheme for the definition of these codes.
(Eq. 1)
whereby Sk is the SMILES atom i.e. one elemental symbol (e.g. C, N, and O) or two symbols which cannot be examined separately (e.g. Cl, and Si); SSk is a combination of two SMILES atoms; similarly SSSk is a combination of three SMILES atoms; CW(Sk), CW(SSk), and CW(SSSk) are the correlation weights of the above-mentioned attributes of SMILES; NA is the number of attributes in SMILES; α is 1, i.e. the presence of rings is involved in building the model, or 0 i.e. presence of rings is not involved in building model). HARD is a descriptor characterizing SMILES as a whole (24). The C5 and C6 are descriptors characterizing rings in the molecular structure. These descriptors are calculated with the molecular graph (23-25). C5 and C6 are codes sensitive to the number of corresponding rings in the molecular structure, the presence (absence) heteroatoms, and the presence (absence) of aromaticity. Figure 1 shows the general scheme for the definition of these codes.
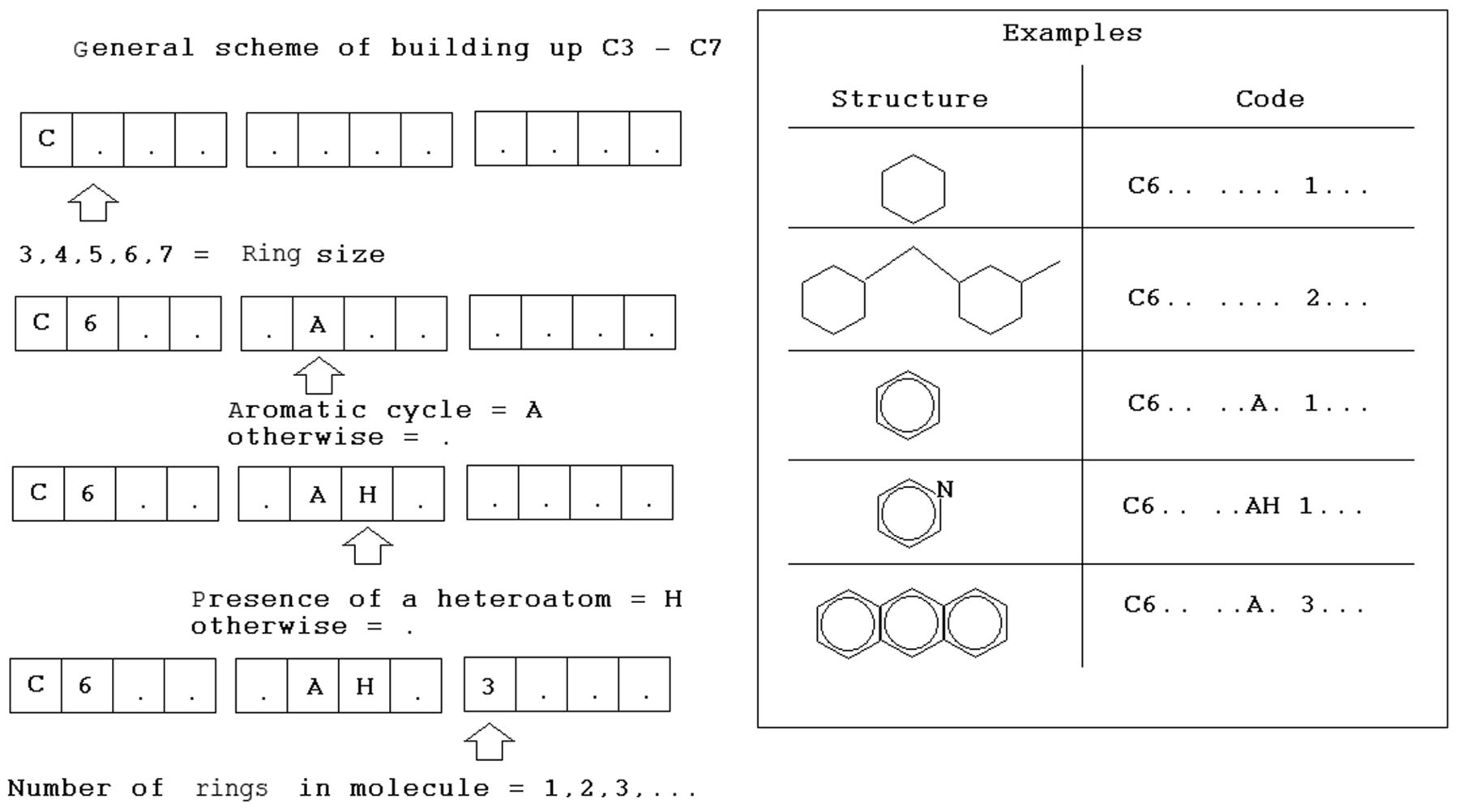
The general scheme of definition of codes reflecting the presence of different rings in a molecular structure.
The numerical data on correlation weights of these features of the molecular structure extracted from SMILES and graph were calculated with the Monte-Carlo method, i.e. the optimization procedure that gives maximal value of a target function (TF). QSAR models were calculated with the Monte-Carlo optimization based on two kinds of target functions TF1 and TF2:
 (Eq. 2)
(Eq. 2)
 (Eq. 3)
where by RTRN and RiTRN are correlation coefficients between the observed and predicted endpoints for the training and invisible training sets respectively. IICCLB is calculated with data on the calibration (CLB) set as the following:
(Eq. 3)
where by RTRN and RiTRN are correlation coefficients between the observed and predicted endpoints for the training and invisible training sets respectively. IICCLB is calculated with data on the calibration (CLB) set as the following:
 (Eq. 4)
(Eq. 4)
 (Eq. 5)
(Eq. 5)
 (Eq. 6)
(Eq. 6)
 (Eq. 7)
The observed and calculated values are corresponding values of the endpoint.
(Eq. 7)
The observed and calculated values are corresponding values of the endpoint.
Having the numerical data on the correlation weights the predictive model is calculated by the least squares method with compounds from the training set:
 (Eq. 8)
The predictive potential of this model should be checked with an external validation set.
(Eq. 8)
The predictive potential of this model should be checked with an external validation set.
The statistical characteristics of the CORAL models for three random splits.
Results
The CORAL models for the pIC50 in the case of using target function TF1 for three random splits were the following:
 (Eq. 9)
(Eq. 9)
 (Eq. 10)
(Eq. 10)
 (Eq. 11)
The CORAL models for the pIC50 in the case of using target function TF2 for three random splits were the following:
(Eq. 11)
The CORAL models for the pIC50 in the case of using target function TF2 for three random splits were the following:
 (Eq. 11)
(Eq. 11)
 (Eq. 12)
(Eq. 12)
 (Eq. 13)
Table I presents the statistical characteristics of these models. Target function TF2 gave better models for all three random splits in comparison with optimization with TF1. The Monte-Carlo optimization without correlation weights for C5 and C6 gave models characterized by reduced predictive potential in comparison with models where correlation weights for C5 and C6 were taken into account (Table I).
(Eq. 13)
Table I presents the statistical characteristics of these models. Target function TF2 gave better models for all three random splits in comparison with optimization with TF1. The Monte-Carlo optimization without correlation weights for C5 and C6 gave models characterized by reduced predictive potential in comparison with models where correlation weights for C5 and C6 were taken into account (Table I).
List of possible anticancer agents according to described models.
Discussion
Having data on several runs of the Monte-Carlo optimization allows the possibility to detect SMILES attributes, which have solely positive correlation weights. These attributes can be qualified as promoters of increase for pIC50. Corresponding computational experiments have confirmed that there are molecular features, which are promoters of pIC50 increase. These are: (i) features of five-member and six-member rings; (ii) branching of the molecular skeleton; and (iii) the presence of double bonds.
Table II presents the molecular structures of potential effective anticancer agents against the MCF7 breast cancer cell line defined according to the above-mentioned conditions, i.e. presence of one five-member ring, two six-member aromatic rings, presence of double bonds, and the bifurcations of molecular skeleton.
The statistical characteristics of models calculated with Eq. 11, 12 and 13 are better than the statistical characteristics of the CORAL models suggested in the original work (1), where the best model was characterized by r2=0.8603, and mean absolute error=0.225 (validation set). Thus, using the correlation weights for C5 and C6 together with modified target function TF2 improves the model for cytotoxicity of 2-phenylindole derivatives against the MCF7 breast cancer cell line.
Conclusion
The IIC is a new criterion for the predictive potential of a QSAR model. The use of the index as a component of the target function for the Monte-Carlo optimization improves the predictive potential of models for the cytotoxicity of 2-phenylindole derivatives against the MCF7 breast cancer cell line. The use of global SMILES codes C5 and C6, which are sensitive to the presence and quality of rings, provides the possibility of improving QSAR models for this endpoint.
Acknowledgements
The Authors are grateful for the contribution of the project LIFE-CONCERT contract (LIFE17 GIE/IT/000461) for financial support. The Authors would also like to thank the Editorial Board for the help in preparation of the article.
Footnotes
This article is freely accessible online.
- Received October 8, 2018.
- Revision received October 19, 2018.
- Accepted October 23, 2018.
- Copyright© 2018, International Institute of Anticancer Research (Dr. George J. Delinasios), All rights reserved
In this issue





{kind=link}
Jump to section
Related Articles
Cited By...
- No citing articles found.